![]() Last week, we set up our Kubernetes cluster. It is up and running, and we are ready to host our first pod/application. Let’s learn how, by taking it step-by-step, we can deploy an application and how to expose it to the outside world. On this week’s blog post, we are going to learn about Pods, .yaml files, and services.
Last week, we set up our Kubernetes cluster. It is up and running, and we are ready to host our first pod/application. Let’s learn how, by taking it step-by-step, we can deploy an application and how to expose it to the outside world. On this week’s blog post, we are going to learn about Pods, .yaml files, and services.
This week, to continue our learning, we are going to deploy the first application.
By deploying the Microsoft SQL (MS-SQL) application on our new cluster, we will expose to Kubernetes Pods, Services, Deployment, and more. Don’t stress too much about all these topics; in this week blog post we are going to focus only on the application deployment. Next week we will learn more about Services, Deployments, and Volumes. Again, don’t stress out over these new terms, these will become easier to understand as I demonstrate each topic.
So let’s get started with creating our:
Kubernetes POD
A Pod is a group of one or more containers with shared storage and network resources; it includes a specification for how to run the containers. Pods are the smallest deployable unit of computing that you can create and manage in Kubernetes. To learn more about Pods, please refer to the Kubernetes official documents by pressing on this link.
Note: When working with Kubernetes application deployments, we will not deploy and manage pods; instead, the best option is to work with Deployments, but more about this later.
Deploying MS-SQL Server Pod
To deploy our MS-SQL pod, we first need to browse to the Doker Hub to learn more about the package and how we can deploy the application. On the Microsoft SQL Server DockerHub page, we need to note the following info to be able to deploy the application:
- SQL Tag: Let’s choose the Ubuntu Tag
Note: Take note of the repository and the tag URL: mcr.microsoft.com/mssql/server:2017-latest-ubuntu
- Requires the following environment flags:
- Accept the EULA: ‘ACCEPT_EULA=Y’
- SA_PASSWORD=<your_strong_password
- SQL Version: MSSQL_PID=Express
After we note these required environment flags, we are ready to create our .yaml file to deploy the SQL application. First, create a new file with editor “vi” or any other text editor, and paste the following lines. Save the file:
Ensure that the format remains as entered above, then save.
Create the SQL POD
After creating the .yaml file, lets call it mssql_pod_deployment.yaml. Now we are ready to execute the deployment and create our first pod and first application. To execute the deployment file, we need to run the following kubectl command:
- kubectl apply -f mssql_pod_deployment.yaml
Running that above command will instruct our cluster to download and deploy the mssql/server:2017-latest-ubuntu image. We can check the deployment process using the following command:
- watch kubectl get pod
After you see that our mydb pod been created, you can press Ctrl+C to exit. You can run the following kubectl command to check the deployment application logs:
- kubectl logs mydb
Ensure that there is no errors with the deployment. Also, you can run the following kubectl command to get more info about the Pod details:
- kubectl describe pod mydb
From the output, you can learn about the MS-SQL edition we just deployed, its password, messages, and application port.
Connect to the POD SQL
Following the steps up to this point, you will realize now that a connection from the outside world to the newly deployed SQL server is impossible; We have not exposed the pod to the outside world. This is a simple fix. All that we have to do is run the following kubectl command; again, don’t stress about the command details, at this stage we just running through a demonstration before we start breaking down each topic and learning more about it.
- kubectl expose pod mydb –type=NodePort –name=mydb
After you have run the above command, you will be able to confirm the connection details of the pod using the following kubectl command.
Note: we are determining the application external port details:
- kubectl get services | grep mydb

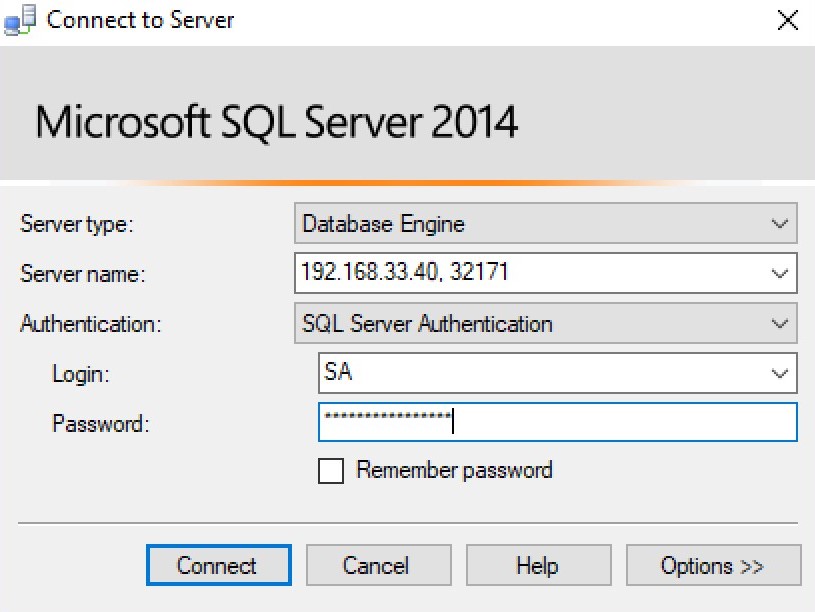
From the screenshot above, we can determine that the external port number is: 32171.
To connect to our SQL server, let’s use SQL Server Management Studio and connect to the Kubernetes Cluster using the port as shown on the following screenshot:
Summary
When completing the above steps, you will end up with an SQL POD deployed. From that deployment, you can connect and create your own databases exactly as you can with a normal SQL server. Normal SQL server? Unfortunately, no, as any databases you have created will be lost when you re-deploy the POD. So, on our next blog post, I will discuss Volumes and Persistent Volumes; we will need these prior to re-deploying the POD to not run the risk of losing the database or destroying the POD.

[…] our last blog post in Part 2, we learned how to deploy the MS-SQL server. All that is required now is to modify the .yaml file […]
LikeLike