![]() There is no doubt that Kubernetes* and containers are becoming the new modern cloud norm. Instead of running through a complex series of steps to deploy an application on your cloud deployment, you can use this technology to help you speed up your application deployment, management, and remediation time.
There is no doubt that Kubernetes* and containers are becoming the new modern cloud norm. Instead of running through a complex series of steps to deploy an application on your cloud deployment, you can use this technology to help you speed up your application deployment, management, and remediation time.
*Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications. The open-source project is hosted by the Cloud Native Computing Foundation (CNCF). https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
However, if you are not a DevOps engineer or a Developer, this subject will appear at first glance to be too complex to master. Don’t worry, that’s why I’m writing a series of blogs to help you, beginning with this one.
To get you started with Kubernetes, I am going to publish blogs on the following topics every week. Going through each topic will help you understand the task and prepare you to move on to the next one. The coming topics are:
-
- Deployment of a local Cluster, consisting of one Master and two Nodes/Workers
- Deployment of the first application
- Attach a persistent storage, local and NFS
- Deploy Microsoft SQL Server and host the DB on a persistent storage
To keep up with the new technologies, I have been considering learning Kubernetes for some time. I usually ended up putting this aside, as I had other skills as an infrastructure engineer that I also should have considered mastering. However, last year I found myself in a position that told me I couldn’t ignore this anymore; I needed to get started. The good news is that in today’s public clouds, for example, Azure, you can create a cluster without too much hassle. Being now convinced that I had to learn the technology, I manually went through each step to better grasp the finer aspects of the technology. So, let’s start with the deployment of the cluster.
Prepare for Cluster Deployment
To follow the instructions in this section, make sure you have prepared three Virtual Machines with the following specifications:
-
- Linux Ubuntu server (20.04.1)
- At least 2G Ram and 2 vCPU on each
- 20 GB local disk or more
On one of these VMs, we are going to deploy the Kubernetes Master node; on the other two nodes, we are going to deploy the Worker nodes. Before we deploy the cluster, we must prepare the operating system for the Kubernetes cluster deployment.
The following steps should run on all the VMs:
-
- sudo apt-get update && apt-get upgrade -y
- Disable the Firewall: sudo ufw disable
- Disable the local Swap: sudo sed -i ‘/ swap / s/^\(.*\)$/#\1/g’ /etc/fstab or edit the /etc/fstab Note: Add ‘#‘ at the front of the swap line:
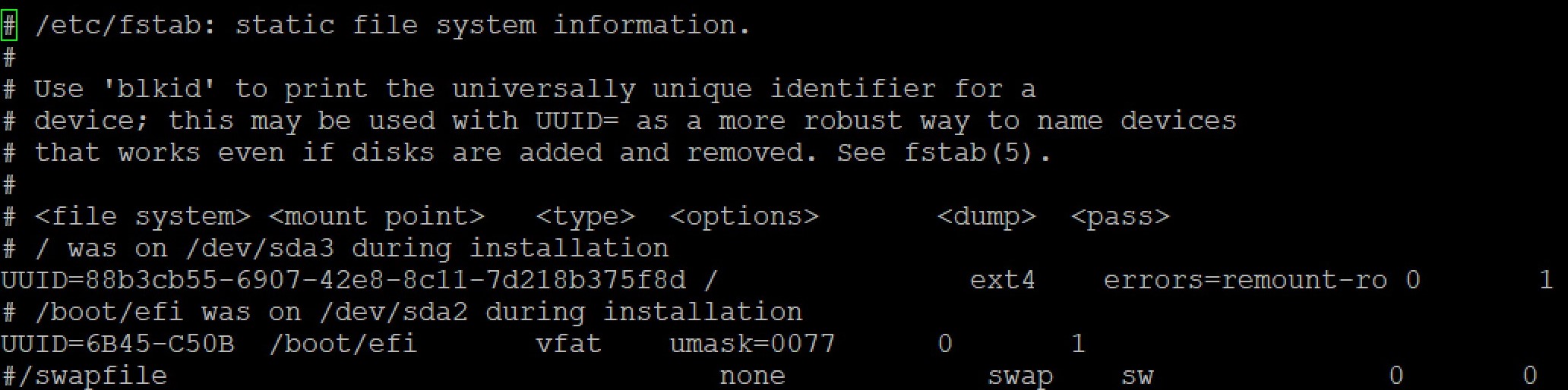
-
- Then run: sudo swapoff -a
- Enable the ip forwarding permanently: edit “/etc/sysctl.conf” and look for line “net.ipv4.ip_forward=1” and un-comment it. After making the changes in the file, execute the following command: sudo sysctl -p
- Deploy Docker: sudo apt install -y docker.io
- Start Docker Service: sudo systemctl enable docker.service –now
- sudo apt-get update && sudo apt-get install -y apt-transport-https curl
- curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add —
- sudo apt-add-repository “deb http://apt.kubernetes.io/ kubernetes-xenial main”
- sudo apt-get update
- sudo apt-get install -y kubelet kubeadm kubectl
- sudo apt-mark hold kubelet kubeadm kubectl
When those steps above have been run on each of the VMs, the OSs are now prepared for the deployment of Kubernetes. We can move to the next task, which is:
Creating the Kubernetes Cluster
To deploy the Kubernetes Master node VM, we must run several additional commands, as follows:
- Initiate the cluster: kubeadm init

- After completing the kubeadmin initialization, you must run the following steps as a regular user (not root):
- mkdir -p $HOME/.kube sudo
- cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
Join the Node/Worker to the Cluster
After the cluster is up and running, we are ready to join the other two VMs as worker nodes to the cluster by following this command:
- Copy the Node Cluster join command and run on each node (this line can be found on the output of the kubeadm init):
- sudo kubeadm join <control-plane-host>:<control-plane-port> –token <token> –discovery-token-ca-cert-hash sha256:<hash>
Last command on the Master Node
Finally, and because we are deploying our cluster locally, we must deploy the network policy by running the following commands:
- curl https://docs.projectcalico.org/manifests/calico.yaml -O
- kubectl apply -f calico.yaml
Summary
On this blog post, I took you through the steps necessary to build you an on-premises Kubernetes cluster based on the Ubuntu OS. If you follow those steps we went through above, you will have a ready to go cluster to configure and build our applications in the coming blogs. For now, though, and to get you keen to learn, I will ask you to run several commands to get you familiar with the kubectl command. We are going to use this one quite frequently in the next few blog posts.
- Check the Cluster version: kubectl cluster-info
- Check the status of the Nodes: kubectl get node
- More info about the Nodes: kubectl get node -o wide
If you want to learn more about what we covered on this blog post, you can find more information at the following links:
- Installing kubeadm | Kubernetes
- Creating a cluster with kubeadm | Kubernetes
- Install Calico networking and network policy for on-premises deployments (projectcalico.org)
I hope this blog post will help you to build your first cluster and prepare you for my next blog post about “Kubectl“, “Deploy Pod – Application“, and more. Until then, please share your experience with us all, and if you have any questions, don’t hesitate to ask.

Thanks Hal, looking forward to the next parts of the BLOG!
What I can also recommend to learn about containers & Kubernetes are Nana’s tech youtube videos, eg.:
Kubernetes tutorial for beginners:
Docker tutorial:
Why Kubernetes drops Docker? :
LikeLike
Hi Herbert, thanks for your message and thanks for reading my blog. Indeed, Nana’s videos are super great – I learn a lot from them too and thanks for sharing.
LikeLike
[…] and two configured as K8 Worker nodes. You can learn how to deploy the K8 cluster by reading my previous blog post. To keep all the information on one blog, I will quickly highlight the important steps needed to […]
LikeLike