 What does the Backup Copy Job do?
What does the Backup Copy Job do?
It uses the backup files in an existing Veeam Backup Repository as a source to create a new set of backup files in a secondary repository.
It is a secondary job in Veeam Backup and Replication which helps to make additional copies, in either a local or offsite location, making it possible and easy to follow the 3-2-1 rule.
How does it work?
It grabs blocks of data out of backup files in the primary repository and creates new backup files with these blocks in a secondary repository.
What is the copy interval?
The copy interval is how often you want to create a restore point in the second repository. This can be the same frequency as the primary backup job, or less frequent.
How does the Backup Copy Job handle archives?
It uses the idea of GFS (Grandfather, Father, Son) to creates a separate, independent restore points, weekly, monthly, quarterly or annually. It is designed to allow you to keep a gradually declining granularity of backups as independent restore points.
Examples: It’s August 2nd 2017, and I’ve been creating a single daily restore point running this job since September 8th 2014.
I have configured my GFS setting like this:

I’ll have the following restore points available to recover from:
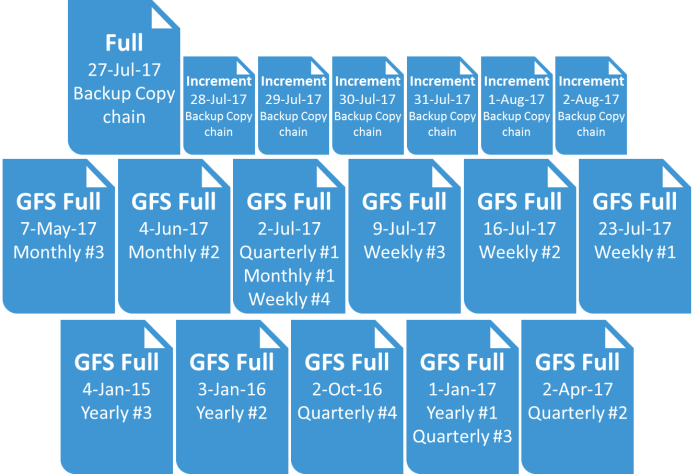
If I configure my job like this:

I’ll have the following restore points available to recover from:
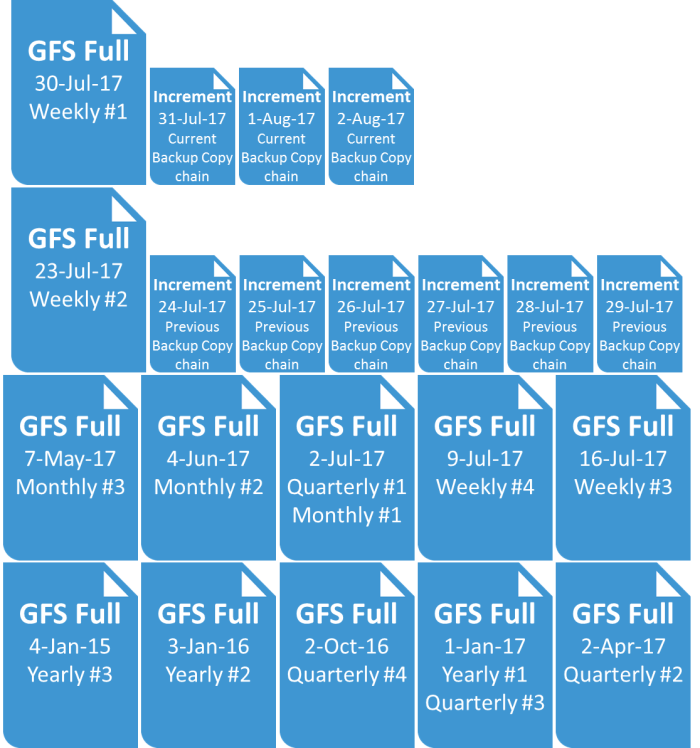
What is a merge?
Merge is the process of taking the oldest incremental backup file and updating the full backup file with it. The merge will take place every run of the job, after the required number of restore points have been created. If you’re running your job daily, and chose to keep 30 restore points, the first merge will take place on day 31.
The only way to avoid the merge in the backup copy job is to enable weekly archived copied, and select the “Read the entire restore point from the source backup instead of synthesizing it from increments.” This will send the data necessary to build the full backup file from the primary repository to the secondary repository on a weekly basis. It will consume more bandwidth, as this is copying all the necessary blocks instead of just the incremental data. This option is good for deduplicating storage on the target side, as it is easier on the storage to receive and deduplicate a new full, than it is to rehydrate and do the merge process.
Is seeding available?
Mapping or seeding a backup file is available for VM backup copy jobs. This is the creation of the first full backup file locally and transporting this out to the destination and then using this backup as the starting point for the job, instead of sending the first full backup file across the connection. Note the first run of the backup copy job after the seed will take more time, as a full read and compare of the data on both sides needs to happen. A KB article about this is available here: KB1856
Here are some suggested steps:
- Make sure that the regular local backup is running
- Create a temporary local repository and remote repository (the actual destination.)
- Create the backup copy job to the temporary local repository
- Let the job run to create the full backup file
- Pause the job
- Copy the files from the temporary repository onto your portable drive
- Take the portable drive to the remote location
- Load the files into the correct location in the remote repository
- Rescan the repository
- Reconfigure the job to point to the remote repository, and map the backup files.
- Re-enable the job
How can I get data over the WAN faster?
Enterprise Plus edition of Veeam Backup and Replication includes source and target WAN acceleration software, which can be installed to reduce the bandwidth consumed when sending Backup Copies (or replicated VMs) from one site to another over a WAN. The software is installed on a windows system at each location, and uses global deduplication to identify the smallest piece of data that needs to be sent across the connection. (Effectively trading processing the data for bandwidth reduction.)
The Enterprise edition of Veeam Backup and Replication includes the source WAN acceleration software, which can be installed on a windows system at the customer site where the customer chooses to send backup copies (or replica VMs) to a cloud connect service provider, who provides the target infrastructure.
How can I keep Backup Copy data safe?
You can use encrypted VM backup files as a source for Backup copy jobs, if the backup copy job is the created on the same backup server as the primary backup job. You can choose to encrypt the backup copy files at rest in the remote repository, the source backups do not need to be encrypted.
If there are concerns around air-gapping the data in the target repository, consider sending the data to a cloud connect service provider, as the cloud repository will not be visible at all from the tenant network. (Cloud Connect for Enterprise can also be used, if there is desire to provide service provider side of cloud connect within an organization.)
How can I use the backup copy job to follow 3-2-1, without maintaining the target infrastructure?
Contact a Veeam Cloud Connect service provider and allow them to provide the offsite location for you to use. We encourage the use of Backup Copy Jobs to Cloud repositories, as they decrease the impact on the production environment. You can choose to encrypt the data in the Cloud repository. From a Service provider point of view, it is a good idea to keep in mind that the tenants chose if they want to encrypt the data in the cloud repository, and deduplicating storage cannot will not provide much deduplication of encrypted data.
Can I offsite my Veeam Agent data with the Backup Copy Job?
Yes, note that all backup copy jobs are configured in the Veeam Backup server. Any edition of Veeam Backup and Replication, including Veeam Backup Free can create agent backup copy jobs. The agent license needs to be installed in this backup server. Mapping or seeding is not currently available for agent backup copy jobs.
Does the source backup job affect the backup copy job?
Backup copy jobs can pull data from any VM backup, forward, reverse or forward forever backup files. In the target repository, there will either be forward forever or forward incremental chain. Note that if per-VM backup files are *not* used in the target repository, all VMs in the backup copy job must be backed up by the primary backup job(s) using the same block size.
How does the Backup Copy Job work with per-VM backup files?
Per-VM backups files allows the ability to have multiple VMs in a job and create a separate chain of backup files in the backup repository for each VM, instead of having 1 big chain of backup files that contains all the VMs from the job. This option is available in Enterprise and Enterprise plus editions, and is commonly used in Scale Out Backup Repositories, Deduplicating storage, and cloud appliances. More space is consumed in the repository, as the deduplication between the VMs is no longer available. Per-VM backup files is a setting in the repository. In the Backup Copy job, the source and/or destination repository can be set to use per-VM backup files.
Using per-VM backup files in the target repository will allow you to create a single job with a mix of VMs backed up in the primary repository with different block sizes
What are the limitations of the Backup Copy Job?
- It can only contain 1 type of backup (no mixing VMware VMs / Hyper-V VMs / Windows Agents / Linux Agents)
- It cannot create granularity in the second repository that doesn’t exist in the primary. (If your primary job runs daily, you can’t create hourly backups in the secondary.)
